從AI繪圖到ChatGPT,AI工具正在短時間內不斷地突破我們的認知界限。
但這些AI工具的發展似乎仍舊沒有停下來的跡象,反而越來越迅速,不斷取得新的進展——
就比如說,最近的研究發展讓AI擁有了“讀心術”。
前幾天,twitter上的一則推文,介紹到“有研究團隊成功讓AI讀取了人類的思想”,引起了一波網際網路的轟動。

有網友表示,AI技術更新的速度是如此之快,而我們正在見證AI領域最瘋狂的發展時期。
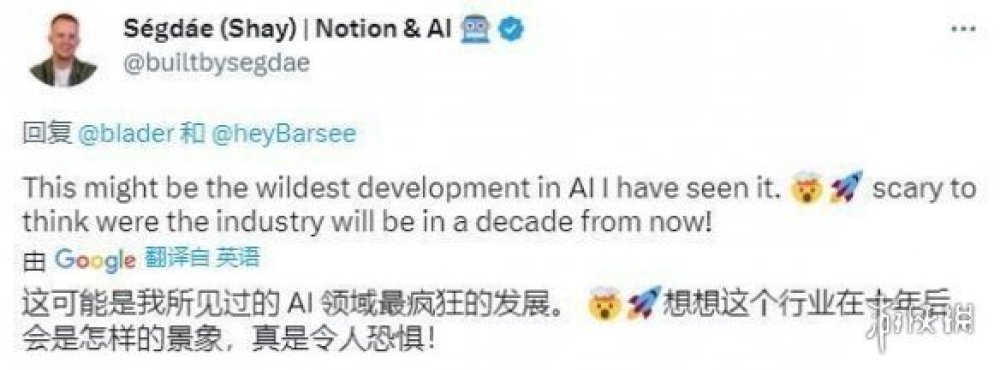
雖說一開始不太相信,但在看過具體的步驟之後,我也只能感嘆道:真的太神奇了。

這項研究,是由大阪大學的前沿生物科學研究院的兩位教授Yu Takagi和Shinji Nishimoto完成並發表的。
他們在去年的12月發表了這篇論文,而該論文目前已被CVPR 2023(世界頂級的計算機視覺會議論文期刊)收錄。
準確的講,研究團隊讓AI具備的是一種“讀腦術”的能力。
研究人員通過fMRI(功能性核磁共振成像,相比於傳統的MRI結構性成像更注重大腦的實時活動)獲取大腦特定部位的活動訊號,再將這些訊號投入stable diffusion這一AI圖片生成工具中,最終利用AI合成相關的圖片。
就比如說,在看到這些小熊、飛機、風景等等照片之後——
人眼所看到的事物
在一系列操作之後,AI能夠呈現出以下這樣的影象。
雖然相似度並沒那麼高,但AI已經準確的抓住了每張圖片的特徵,也能夠讓大家很好的辨識出來了。
AI所呈現的影象
但如果你覺得,這就像《哈利波特》中的“攝魂取念”一樣簡單?
那你就大錯特錯了。

實際上,想要實現這一目的的具體步驟非常複雜,在這我就簡單描述一下:
首先,研究人員需要記錄被實驗者看到圖片之後的大腦活動資料。
這些資料被分為兩類,一類是較為初級視覺皮層訊號,另一類是高階視覺皮層訊號。

當然,僅僅只有這些視覺皮層的訊號,是很難呈現一張完整的影象的。
這時候研究人員用到了能夠生成影象的AI擴散模型——Stable Diffusion。
或許很多人已經使用過這類以擴散模型(Diffusion model)為基礎的AI繪圖工具。
和大多數同類AI繪圖工具一樣,只要輸入文字或者匯入影象進行參考,就能生成想要呈現的圖片。

咒文詠唱
不過在研究中,Stable Diffusion的詳細使用方式則要複雜一些。
研究所用的Stable Diffusion主要由三個結構組成,分別是圖片編碼器、文字編碼器和圖片解碼器。
前面提過,此前研究記錄了初級和高階兩類視覺皮層訊號。
而在這一環節,研究人員將初級的訊號記錄到圖片編碼器上,再解碼成一張圖片(被稱為z);同時也將高階訊號記錄在文字編碼器上,解碼成相關的文字(被稱為c)。
最後,通過將解碼之後的圖片和文字再次結合,輸入給Stable Diffusion,就能夠得到一張最終生成的圖片(zc)。
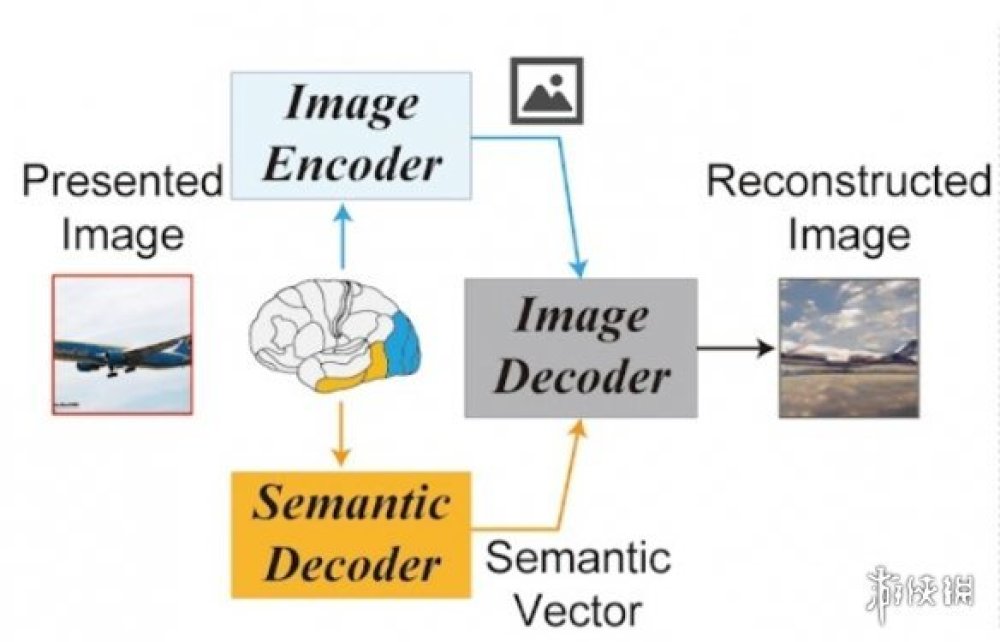
生成圖片的流程
看到這裡,你是不是已經感到頭昏眼花了呢?
然而這僅僅只是我簡化了之後的描述,實際上只要你點開文獻,你就會發現要實現這一目的,其中還有更多的實驗細節。
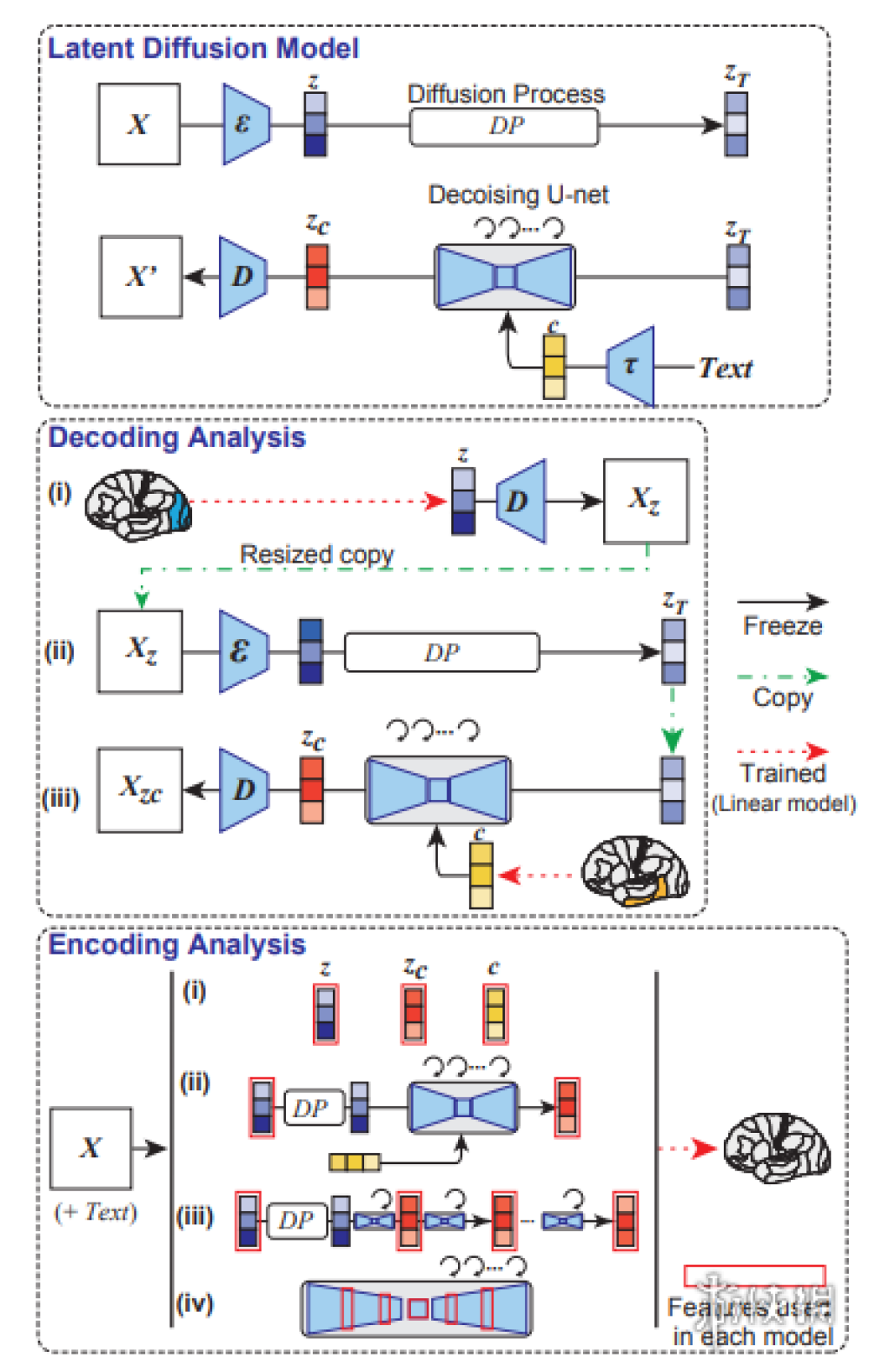
研究的整體流程
所以在此我也想再感嘆一句:研究團隊真的太厲害了。
可以發現,如果單單只是看由圖片編碼輸出的圖片(z),很多情況下只是顏色和結構相似,但完全不能呈現實物;而只由文字編碼輸出的圖片(c),內容是符合的,但整體畫面和原圖重合度並不是很高。
只有將兩者結合,才會生成一張既符合影象佈局和結構,又符合實物的畫面,更接近真實所看到的影象。

不同情況所生成的畫面,zc重合度最高
事實上,一直以來,就有著不少研究團隊致力於研究將大腦訊號生成圖片。
像是早在2011年的時候,加州大學伯克利分校的研究團隊就已經完成了解碼大腦訊號並生成圖片的重建。
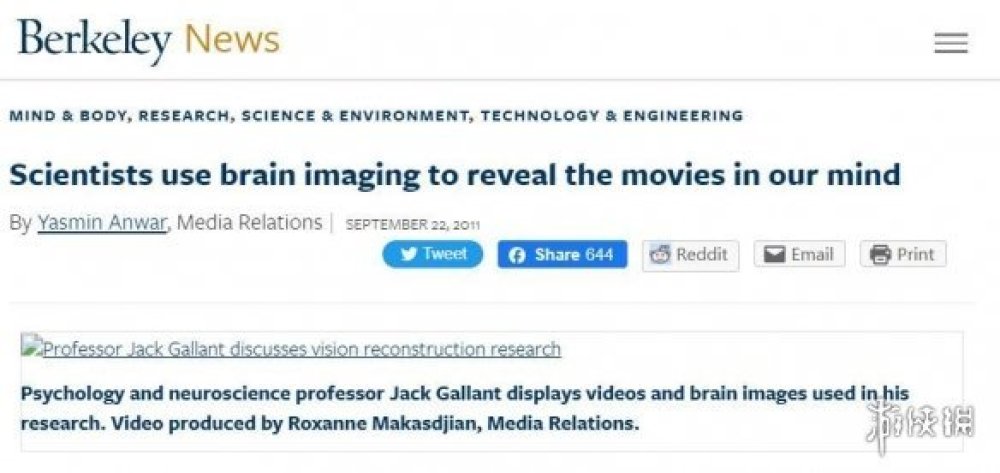
不過由於當時fMRI獲取資訊科技和圖片生成模型並不成熟,研究過程中所生成的圖片並不是很清晰,雖然輪廓有了,但往往看不清實體。
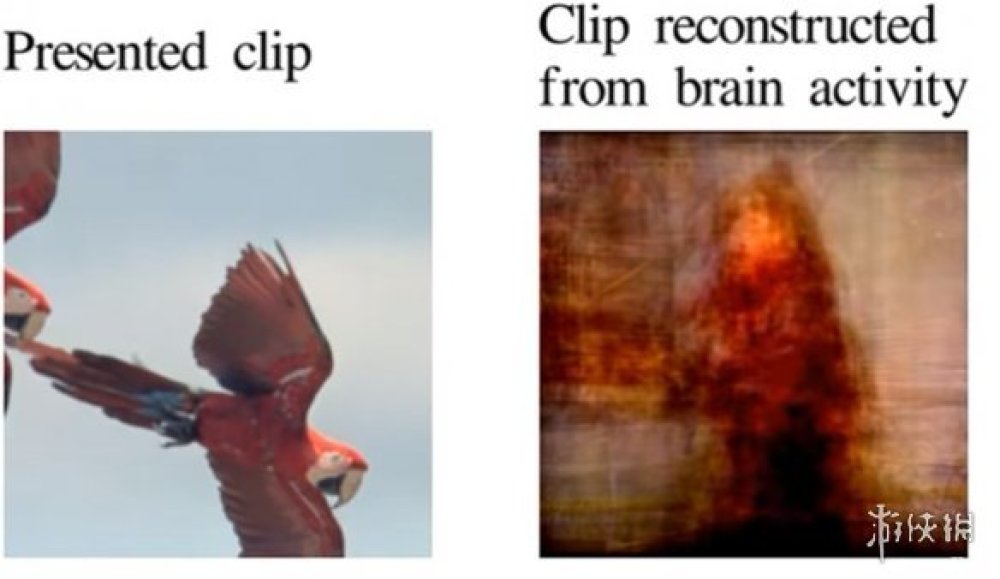

左:實際片段 右:大腦活動生成的片段
而隨著人工智慧的發展,AI在圖片生成的應用,也讓這一研究取得了巨大的進步。
去年一月份,有團隊利用GAN模型,同樣通過fMRI收集到的大腦訊號,重建所看到的人臉影象。

說起來,其實GAN才是AI繪圖的“鼻祖”。
最初的GAN難以生成高質量的影象,而現在的GAN已經可以這些模型從生成模糊的人臉到具有不同約束的高清逼真圖片。
GAN模型生成的圖片
這一團隊利用GAN作為圖片生成模型,能夠很好的還原出大腦所見的人臉形象,具有一定的辨識度。

左邊的stim是顯示給測試物件的人臉,S1S2是不同測試物件從fMRI資料中生成的面孔
不過,隨著以Dall-E、Stable Diffusion為主的“擴散模型”的橫空出世,這類AI圖片生成工具,不論從真實程度亦還是想象、理解能力,都更為符合人類的想象。
大阪大學的這項研究,首次利用擴散模型進行實驗,並且得到了一個還算不錯的成果,我想也算是在“AI重現大腦記憶”這一領域立了一塊不小的里程碑。
對於這一研究,不少人報以積極的想法,並且開始暢想它能夠對社會做出的幫助:
通過大腦直接透露資訊,可以讓我們更好的去了解一些無法進行口頭交流的人的思想,例如中風患者、植物人、漸凍症病人等等。

或許每個人都想知道自己的夢境。通過這種“神經視覺化”的方式,也能夠更好的幫助我們理解和重現夢境中的意義和象徵含義。


甚至這種不需要依靠語言交流的方式,還有可能實現不同物種之間的對話——相信在未來,當這種“心靈交流”的APP上市後,一定會成為養寵人的必備應用。
但另一方面,不少網友也對此發出了反對的聲音,表示這一技術“細思極恐”。
網友們截然相反的想法
在對於AI未來方向的討論中,有的人提出了可以通過提取記憶,用來在法庭上提供證據。
在《黑鏡》的一集《鱷魚》中,就構建了這樣一個“沒有冤案”的烏托邦社會。

在這一集裡,人類研究出了一款能夠挖掘記憶的機器。這個“取證器”在案件審查時得到了廣泛的使用。

每當有案件發生,通過提取當事人和其他目擊者的記憶,整個事件能夠被完整的還原,因此辦案效率也得到了大大的提升。
但是,當人類能夠檢視別人的記憶,那麼同時藏在記憶深處的個人隱私也要面臨被迫暴露的風險。
在劇集中,你會看到,幾乎每一位使用取證器的人,都有自己的隱私和祕密暴露在大眾的眼光下。
出車禍小夥的祕密是和一面之緣的路人一見鍾情,但他從未挑破彼此的感覺;而牙醫的祕密是偷窺對面樓酒店的裸男洗澡,危及到了個人的聲譽——

當提取人類的記憶用於取證時,順帶的是他所有被遮掩和隱藏的資訊也會被揭示出來,無法再保持隱私性。
隨著科技的發展,不僅僅是AI的“讀心術”面臨著隱私暴露的問題,近年來討論熱度非常高的“腦機介面”同樣有著此類的擔憂。
腦機介面是一種直接將人腦訊號與計算機或其他外部裝置相連的技術,通過捕捉和解讀腦電訊號,使人們能夠通過意識控制外部裝置,比如電腦、輪椅、假肢等。
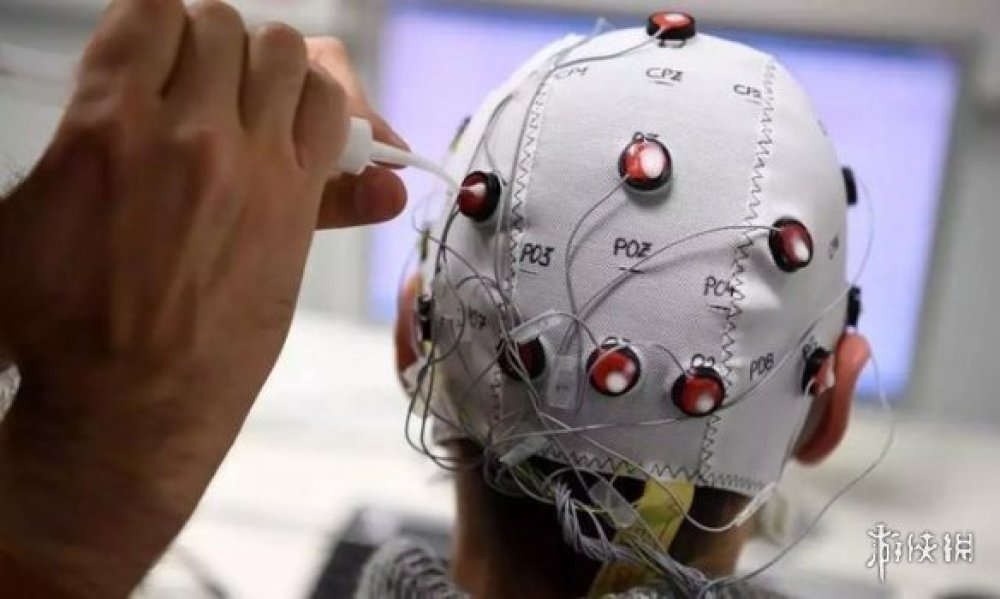
但在通過腦電波等訊號,將人的內部思維活動轉化為可以被外部裝置讀取和解讀的形式之後,腦機介面也將讓人類的思維變得更加“透明”。
在科技服務於人類的同時,人類似乎在朝著“思維透明”這一方向同步前進著。
在大劉的《三體》系列小說中,描述了三體人“思維透明”的概念。
三體人的思維是完全公開和透明的,他們不會撒謊,同時沒有任何隱私或祕密。這種透明度的實現是通過三體人之間共享意識的方式實現的,他們能夠像網路一樣共享彼此的思想。

但在我看來,這種透明化在人類社會是完全不適用的。
這意味著其他人可以輕易地獲取到我們的個人資訊和思想,從而侵犯我們的隱私和安全。黑客或者惡意組織可以利用這種能力來獲取重要的資訊或者進行攻擊,這會對個人和社會造成極大的威脅。
不僅僅是個人隱私的洩露,思維透明化還可能導致一些潛在的人權問題和道德問題,對於社會的打擊也是巨大的。
在大資料時代,越來越多的資料和資訊被數字化和網際網路化,個人隱私的洩露也一直困擾著所有人。
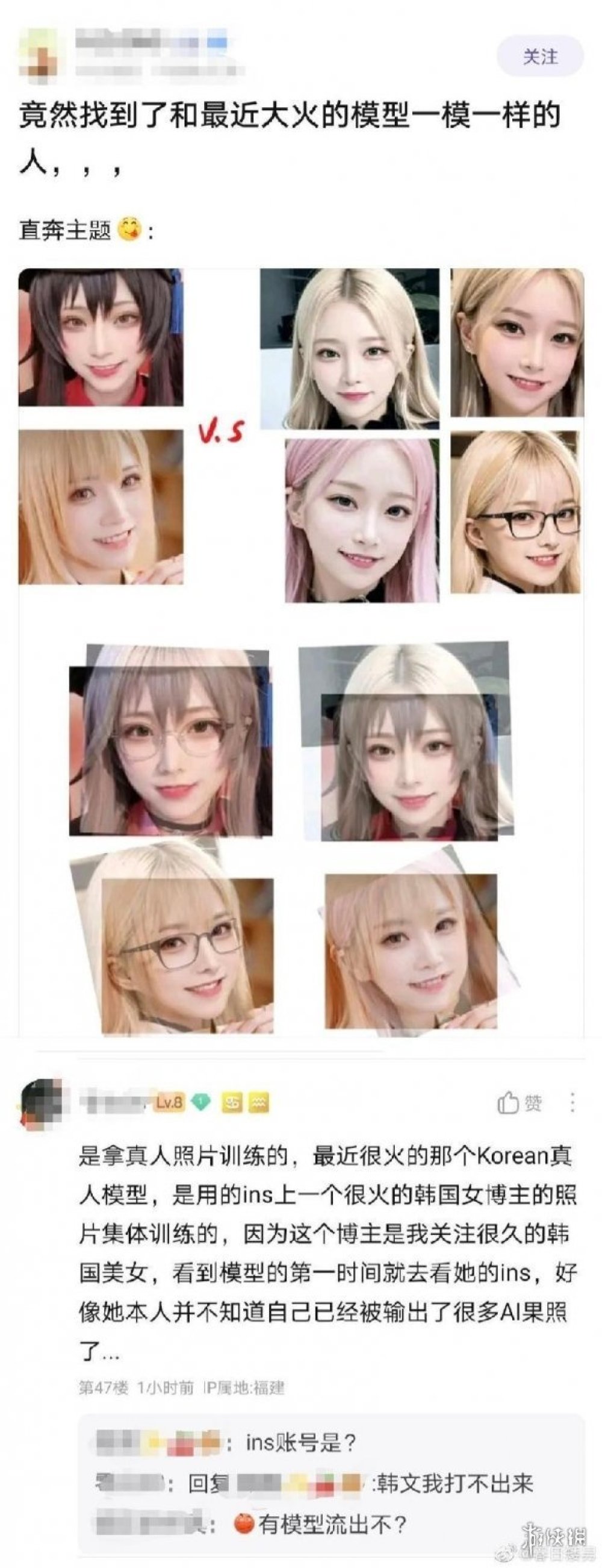
就拿最近火爆的賽博COSer來說,也已經有人扒出這些AI圖片是由一位韓國女博主的真人照片集體訓練的,甚至已經有人拿她輸出了不少不雅的圖片。
再說回AI擁有“讀心術”這回事兒。
現在看來,想要真正實現“心靈交流”,似乎還有很長一段路要走。不過,這一新興的研究方向必定會帶來許多潛在的倫理問題,特別是涉及到個人隱私和權益的保護方面。
而這時,我想研究人員也該採取一系列措施,引導研究向著合乎倫理和社會價值的方向發展。
 舉報免責宣告:本文來自騰訊新聞客戶端創作者,不代表騰訊網的觀點和立場。
舉報免責宣告:本文來自騰訊新聞客戶端創作者,不代表騰訊網的觀點和立場。